 accesses since March 30, 2001
accesses since March 30, 2001 copyright notice
accesses since March 30, 2001
copyright notice
accesses since March 30, 2001Welcome to the third installment of DL Pearls.
Last month I referred to a digital library as an "island" in the anatomical sense. To review, just as anatomical islands are clusters of cells that differ in structure or function than those of the surrounding tissue, so digital libraries are clusters of documents whose structure or function is different from other documents within the surrounding digital network. As I mentioned last time, digital libraries all share the same object-level structure, i.e., are interwoven hypertext sites in which all underlying components are interrelated to one another by means of similar infrastructures. The indexing and query support regime used in the ACM Digital Library is Oracle's Intermedia.
This month, I'll explain how the production process works. As Figure 1 shows, the production environment involves a non-trivial amount of work. Our starting point will be the acceptance of a manuscript by, in this case, an ACM journal editor.
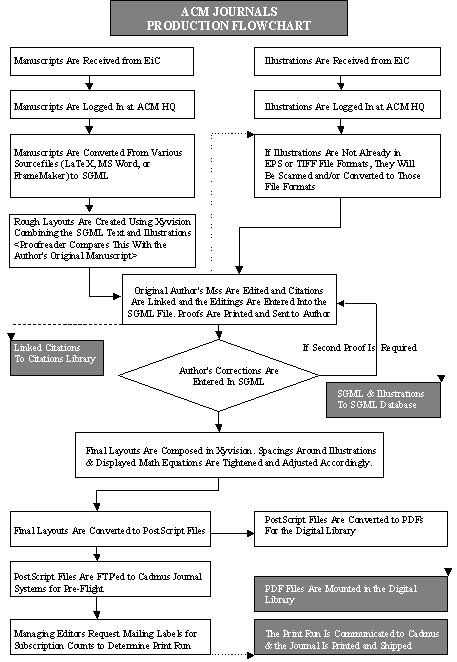
FIGURE 1
But first, go to the ACM digital library (www.acm.org/dl) and conduct a search. In this case, we'll choose a Title search for the exact phrase "electronic commerce" (Figure 2). Once you have the search results, click on "Full Listing" from the View menu. Our current target will be an article in the Dec., 1996 issue of Computing Surveys. To read the full text, click on the PDF icon and you have an electronic copy of the article. Simple enough. But to get you to this point, ACM had to go though considerable effort.

FIGURE 2
Our starting point is on the top-left corner of the ACM Journals Production Flowchart in Figure 1. The first major effort is undertaken at step three, where all manuscripts are converted from their original source format to SGML. SGML is a structured markup language that tags the meaningful, semantic units of documents. There is a fundamental issue involved in the decision to use SGML: ACM decided in 1991 emphasize structure over presentation in its Digital Library so that the contents could be indexed, clustered and retrieved conveniently. An alternative approach would be to use some sort of "digital ink" environment that would emphasize presentation over structure. We'll return to this topic in a forthcoming column. (If you're interested in the future of electronic publishing, see my article "A Cyberpublishing Manifesto" in the March, 2001 issue of CACM.)
These SGML files are then linked directly to the ACM Citations Library - the cement, if you will, that holds all of the Digital Library's contents together. A similar process takes place for artwork (see top of column 2). The SGML text and relevant artwork are then merged into the SGML database that is the heart and soul of the ACM Digital Library.
The next step is to create the "presentation" form of the document. The first phase is the composition phase. In the case of the DL this is done in XYvision. The final layouts are then converted into PostScript, whereupon two separate production streams are created - one for hardcopy, and the other for the PDF mounting in the Digital Library. In a nutshell, that's how the PDF file behind the icon mentioned three paragraphs back came about. While it may look simple, this production process involves several vendors, several software packages, and a bravura performance by the ACM Publication's staff.
But ACM is not stopping there. We are working with a group at UIUC (University
of Illinois Urbana-Champaign) to take those SGML files and convert them to html,
so that you, the DL user, can choose your download. PDF or html? We are looking
into some neat ways of cutting production time and complexity down so that both
the print and electronic versions come out faster. And, we are looking at moving
from SGML output to XML. I will have more to say about XML in a future column.
Now, to the letters. This one is from Angela Gehrig of the University of Melbourne:
"When i click on the link 'Find related records' next to any citation in the DL, what happens? Do I get other records/articles with similar index terms to the first? I have used the 'Find related records' link to extend a search, then selected 'search expression' to try to see the logic behind the search result, but there was no search syntax given. There was a message to the effect that 'you have found records related to record no.9886' !"
Thanks, Angela, for your question. For the answer, we turned to Bernie Rous, ACM Associate Director of Publications. Here is Bernie's response to Angela's question:
"In the ACM Digital Library, [FIND RELATED ARTICLES] actually launches a search based on the INDEX TERMS from the ACM Computing Classification System (see http://www.acm.org/class/1998/). The subject matter of each article is classified with CCS categories and terms. The categories of the article in question are matched against the categories of all other articles in the database. The results are listed order of relevance.
Things to note:
1. The actual Relevance numbers are calculated by such abstruse algorithms as to be meaningless in themselves. Their significance is relative to each other. So, if an article has three categories, the highest relevance will attach to other documents that have the same three identical categories; next highest to documents that have two of those categories; and lowest to those that share only one.
2. The CCS is a hierarchical tree. This fact is NOT used in the FIND RELATED ARTICLES search. It is an exact match only. So, for example, if an article has been classified under "deadlocks" which occurs within the tree under "Operating Systems, Process Management", only other articles indexed with "deadlocks" will be returned, rather other articles classified at the higher or more general level "Operating Systems, Process Management."
3. When the CCS subject categories are applied to a document, one of them is always consider PRIMARY, or central to the subject matter of the work. All others are equally considered as secondary subject categories. Again, this fact is NOT used in the FIND RELATED ARTICLES search. It would be very useful in weighting the results for relevancy. In the near future, this distinction between primary and related subjects, which we maintain in the database, will be used in the search. Right now, all categories are treated as equal for establishing relevance."
And thanks, Bernie, for the clarification.
Remember, send questions and comments to dlpearls@acm.org. We're here to help
Hal Berghel