 accesses since September 7, 1998
accesses since September 7, 1998  copyright notice
accesses since September 7, 1998
copyright notice
accesses since September 7, 1998 Push technology remains hot in 1998, even if the term has fallen out of favor. Now that we've passed through the initial wave of excitement, it seems an appropriate time to re-visit push technology and try to place it in some technological perspective. Some push adherents would have us believe that push technology might amount to the last technology "silver bullet" of the century. Push detractors view the technology as a mistake carried through to perfection. As we shall see, the truth lies somewhere in between.
First, a point of nomenclature. The phrases "push technology" or "push-phase technology" found wide use in 1996-7. Because of the uproar from MIS managers over the excessive bandwidth consumed by "push-enabled" clients, the term "push" in management circles came to mean "bandwidth bandit." As a result, 1998 has spawned a stable of euphemisms for push:
"webcasting," "focused multicasting," "active business intelligence technology," "smart information delivery," "electronic delivery management," and so forth. Rather than try to sort out subtle differences in meanings, we'll continue to use the "push" as a covering term. A push by any other name...
Figure 1: A demonstration of Netscape's original server-push idea via
the World Wide Web Test Pattern.
Semantics aside, the first lesson to learn about push technology is that it isn't new. If we define "push" technology as a tool to distribute information without requiring specific requests from the information consumer, the deployment of "push-phase" information delivery dates back to the late 1800's with the creation of the wire services and the teleprinter networks. United Press International, Associated Press, TASS and Reuters are all information providers that were organized for purposes of "push" communication. The same is true for Bloomberg in the financial services area. In addition to being the mobster who launched Las Vegas, Bugsy Siegel was also the first Mafiosi to harness push technology with his nation-wide bookmaking wire service in the 1940's. Email is a 1:1 push protocol in its simplest form, and alias files and Email distribution lists are 1:many push protocols. In fact, Email also represents the point in push-phase technology evolution where the push became digital. Perhaps the latest stage in push is built within computer assisted cooperative work (CACW). Push has been with us for some time, even though it isn't obvious that we have learned much from our experience with it.
So we can see current push technologies of extensions of earlier successes. Like Email, they are both digital and network-based. But, unlike Email, the modern delivery mechanism is modeled after the metaphor of telecasting rather than those of digital information access and delivery. Our technical lexicon for push-phase information access has grown from radiobroadcasting, telecasting, re-broadcasting, simulcasting, broadcasting and narrow casting to include "net casting", "web casting", "group casting", "personal casting," - and now an ever-growing group of euphemisms like "intelligent business information acquisition" which masquerade for push, but without the negative, "bandwidth bandit" connotation.
As I mentioned in an earlier column on information overload (Communications of the ACM, Feb. 1997), current Web "push" technology is a cousin to the dynamic updating technology which appeared first in Netscape's browser in 1995. The idea behind dynamic updating is that there are situations in which it is desirable to continuously update Web browser windows with dynamic, changing information. Multi-cell animations were an early application, as were slide shows, automatic re-direction - as in the case of passing through a splash page to get to the main menu, digital "ticker tapes," etc. In all of these cases, the dynamic updating was designed to overcome the disadvantages of the Web's "stateless" protocol which disconnects the client-server connection immediately after each transaction cycle (vs. ftp and telnet which maintain transaction "states"). In addition to precluding a transaction "memory," the Web's stateless orientation prevents the sequencing of downloads without time-consuming, end-user involvement.
Dynamic updating, at least in Netscape's sense, took one of two forms: server push and client pull. Server push refreshed information displayed on the client through pre-determined, timed, server-initiated transmissions of HTML documents. However, this approach is server-invasive, requiring special server-side executables to create and deliver the refresh stream, and accordingly server push has fallen into disuse (a "deprecated feature", in Web terminology).
Client pull, on the other hand remains in use within the Netscape community for the display of constantly-updated HTML pages. Unlike server push, client pull requires no special programs to operate. The Web browser client initiates an HTTP connection and request for information from a server when it sees a particular token of the <META> tag in an HTML document. To illustrate, the tag
<META http-equiv="refresh" content="5; url=http://www.widget.com">
would cause a pull-compliant browser to refresh the current browser window with the document at http://www.widget.com 5 seconds after loading the current page. Without a URL specified, the browser will refresh itself with a re-load of the current page. The "pull" is shut off as soon as a document is reached which does not have a refresh <META> tag. (Interactive demonstration server-push and client-pull, along with a slew of other browser features and enhancements, may be found on the World Wide Web Test Pattern Website at http://www.uark.edu/~wrg/)
For both server-push and client-pull, the idea is a simple one: provide data downloads without requiring user intervention. However, early server-push and client-pull technologies were deficient in one major respect: they were context- and content-insensitive. That is, all accesses to a URL - whether pushed or pulled - produced the same results for all users at any given moment in time. This context/content insensitivity became the bete noir of Netscape's dynamic updating technology because it produced an information access and delivery system that wasn't scalable - the delivery of numerous, complex, timely and personalized documents require as many URL's as there are documents. In order to minimize information overload, some mechanism needed to be created to build the content and context sensitivity into the push technology, itself.
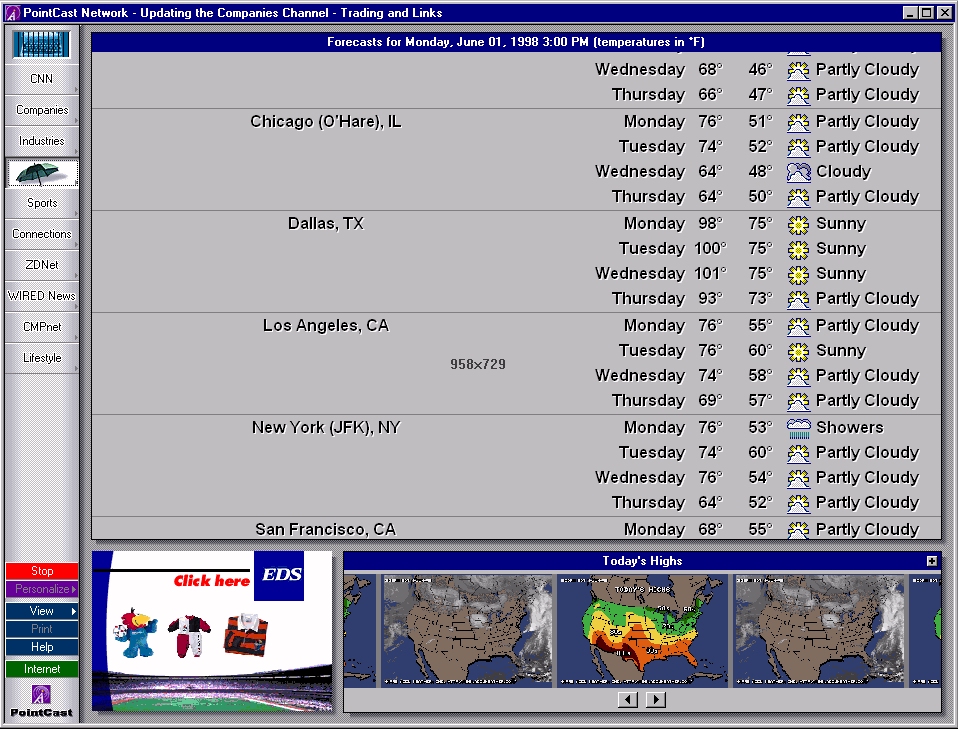
Figure 2: The Pointcast client at work. In this case, the topic is
weather. Other categories or feeds appear in left frame.
In current push environments, the content is handled via "content identifiers" while the context is provided through "channels." In this way, downloads are pre-filtered on servers and organized, consolidated and distributed as coherent streams. Also, push-phase access is desktop-compatible and stand-alone, rather than browser-centric (as in helper apps and plug-ins). This liberates both information consumer and information provider from dependence on Web-based clients. Today's info-pushers are first and foremost in the business of content delivery, along the way developing the client-server technology they need accomplish their goal.
Currently, the push paradigm is "targeted and solicited.". Individuals voluntarily "subscribe" to network information providers through intermediate push delivery systems. Push environments tend to have several things in common.
For one, push servers tend to combine the dissemination of both internal content (provided by the vendor) and external content (provided by 3rd parties and routed through the vendor's push server). In addition, all push servers that we know of require proprietary clients, and offer support to varying degree to both Internet (esp. Web), intranet (company internal) and extranet (inter-company, customer and client) information access, although individual emphases may be different. Pointcast, for one, emphasizes Web information more than most, while Wayfarer's Incisa tends to emphasize intranet use. We note in passing that Internet vs. enterprise environments are predicated on different assumptions. Consider for example that Backweb's intranet orientation makes it possible to uttilize Intel's CPU ID capabilities for segmenting content based on the client id (e.g., by power of processor, MMX compliance, internal MPEG support) which simply wouldn't be feasible for the Web. Finally, push clients tend to be free, or at least very inexpensive.
| Backweb | Intermind | Marimba | Pointcast | Wayfarer | |
| advertising-based vs. subscription-based | s | s | s | a | s |
| method (client poll or server push) | client poll | client poll | client poll | client poll | server push |
| content (binary, html, Java) | binary/html | html | html/java | html | n.a. |
| CDF compatible | y | n | n | y | n |
| legacy database access? | y | y | y | n | y |
| interface (proprietary,browser) | proprietary | browser | prop. | prop. | prop. |
| end-user filtering | n | n | n | n | y |
| differential downloading | n/a | y | y | n | n |
TABLE 1: Characteristics of Selected Push Environments
Table 1 lists a few features which are discriminating between push environments as best we can tell from the documents on each vendor's Website. For example, Pointcast (www.pointcast.com) represents a very different business model from its competitors. The Pointcast business model is advertising-based, while others are subscription-oriented. These two approaches create significant differences in the economics of push, just as they do in the traditional publishing industry. And, like it's publishing ancestor, we expect that push business models will eventually blend together as competition forces developers to prowl for additional revenue streams.
All of the push environments that we reviewed for this article except one were actually "automated client pull." The terms "client polling" or "smart pulling" are used in the literature to denote information delivery by automatic client fetching, rather than a server-initiated process. However, since both techniques are transparent to the end-user, not a great deal is at stake at the moment.
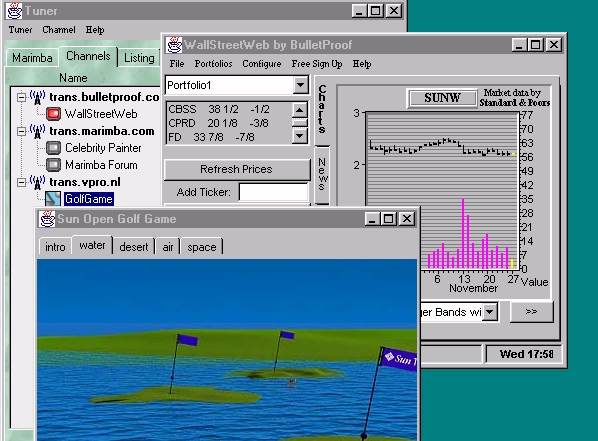
Figure 3: Marimba's Castanet Client. Note three channels are established, the first and third of which are active in separate windows. Interactivity between client and server is automatic and autonomous for each channel.
Push programming is usually handled through a mixture of internal or external "pre-programmed channels" that come from a multitude of sources or "feeds." Typically, a vendor will offer dozens or even hundreds of channels through its server. An exception is Wayfarer's Incisa, which distributes information by complex messaging over a single channel. In all cases, however, the emphasis is on increasing the type, variety and quality of information sources, and filtering them properly. However, not all environments support the same range of content. Some are restricted to HTML while others support executables.
CDF, Microsoft's Channel Definition Format ( www.microsoft.com/standards/cdf.htm), is a proposed standard for push clients that is written in extended markup language, XML (http://www.microsoft.com/standards/cdf.htm).. On this account, a content-description file which would define the structure, nature, currency, and so forth, for each channel could be downloaded with, and define, each Web document and the channel it belongs to. The main alternative at this time, advanced by Netscape, is to handle the meta-level information with scripts, Java and enhanced HTML.
Legacy database access is likely to be critical for applications where the currency of the data is mission-critical. At this writing, several database interfaces are supported, including CGI, Open Database Connectivity, Java and SQL, with Java being the more predominant
There are two basic types of interface for push technology: autonomous desktop clients on the one hand, and the use of existing Web browsers on the other, with the former being the norm. End-user filtering allows the information consumer the luxury of determining the nature of the filtering rather than relying on the judgment of the information provider. Finally, some products support differential downloading of files so that the latest version of a file is downloaded if the end-user doesn't already have it. This is becoming a de facto standard and widely viewed as good of netiquette.
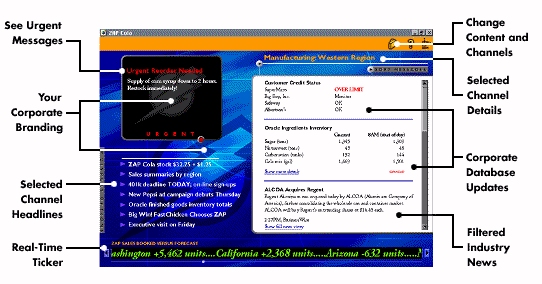
Figure 4: The Wayfarer
"montage" view combining channel, ticker tape, frame and headline views of the
pushed informaiton. Individual views may also be selected
At this writing push technology developers are complementing their peruser technology with advanced proxy server and firewall software to minimize network traffic and information duplication on the intranet's server while increasing its throughput. Security and encryption is also being built in as are expanded intelligent agency and brokerage capabilities to increase the content coherence on the channels.
It is generally accepted that push-phase information technology can offer several advantages over manual, pull-phase information distribution technologies. The following are among the more obvious advantages touted in the trade literature:
Currently, hundreds, if not thousands, of media-rich (if not content-rich) channels are available for push technology use. That these channels provide useful information to some end-user communities is beyond dispute. However, the information processing industry's negative reaction to Pointcast's initial offerings indicates that push technology, as such and in general, is certainly not a silver bullet. So where will the future value of push be?
The two most popular push milieus, Internet and enterprise content delivery, will likely continue to evolve, penetrating ever-narrower, and more focused, market niches along the way. Because of the huge volume and growth rate of Internet resources, we don't ever foresee a one size fits all, "push for the masses" environment because consumers would drown in at best marginally useful information (this relates to our information customization conjecture.
Our view of the future is more of a "distributed push" model where thousands of information providers use push technology to link to specific and well-defined consumers. On the Internet side, push will complement both the Web and email by adding a layer of automated information feeds on top of existing content. However, it is on the enterprise side, it seems to me, that push has the clearest advantages over rival technologies, especially in the areas of differential downloading and automated announcement systems (items 1) and 2), above). For these reasons alone, the future of push in some form or other seems secure.
After the first two advantages, however, trying to determine which features will remain important is difficult because cyberspace continues to re-define itself. For example, a/v streaming via push channels appears prima facie to be a useful application, but loses luster when bandwidth is considered.
Delivery independence is also hard to assess. Since proprietary interfaces are currently the norm, a return to browser centricity will require integration of popular push interfaces into the two leading browsers, i.e., as "plug-ins." Though few would argue that dozens of independent standards for rendering push information is a social good, it doesn't appear that the leading browser developers are very interested in integrating a wide range of push tool plug-ins at this writing. Even Microsoft's CDF, which is as close to a push standard as anything, has yet to be supported by the majority of developers.
In terms of automated document management and managed delivery, we see future push technology evolving coetaneously with brokering services (flash lists, distribution lists, etc.), and recommender systems (cf. www.firefly.com), which develop virtual relationships between information producers and consumers on the one hand, and autonomous information agents on the other. We also see push technology as a core component of Computer Assisted Cooperative Work environments (aka groupware), most especially with respect to differential downloading. Similarly, we see filtering/screening backplanes behind push technology to be an extension of mainstream work in information retrieval and information customization.
Though the future of push seems bright, it gets cloudy beyond applications like differential downloads and enterprise narrowcasting, The real challenge for the push developers will either be to carve out new application gamuts for which push is particularly well suited, or to somehow blend push into the toolbox of desktop suites.
It appears to us that while push-phase information access and delivery, at least in its infancy, is not a "silver bullet," it will play an important - though limited - role in delivering filtered and channeled multimedia, especially in enterprise networks. The next phase of push development will likely be characterized by information-theoretic studies of the recall, precision, fallout and generality of the output. Push maturity will likely reduce the dimension of the push playing field, and weed out some of the players.
Beyond the technology, there are both social and privacy issues which are just now being discussed. We do not know how to measure the long term efficacy and behavioral effects of "passive viewing" (where end-users might stare at a push channel window - perhaps a stock ticker - while on the telephone, or working with another workstation application). Speculation ranges from a "mind-numbing" effect to a highly-useful form of "subliminal" information uptake. In addition, society needs to deal with the issue of the delivery of "sensitive" (perhaps pornographic, inflammatory, etc.) material. It is worth remembering in this regard that erything that can be pulled can also be pushed.
Finally, commercial interests will inevitably drive this technology toward "unsolicited" push so that vendors may advertise through existing distribution channels. To illustrate the point, Pointcast advertisements are not filterable - they are an integral part of the feed. Perhaps we should concern ourself with the question "Will push lead to shove?"
In the end, our skepticism about push technology is based on a simple axiom which for want of another term we'll call Boyle's Law for Cyberspace: data will always fill whatever void it can find. The primary lemma is that even if network overload can be avoided, information overload of the end-user will always remain. Such being the case, client-side solutions such as information customization (cf. http://www.acm.org/~hlb/publications/cb5/cb5.html) must be sought to relieve the pressure from information overload.
In the interest of space, we have restricted our discussion to a few of the more popular "push" products and vendors. Additional vendors and their Website URLs are listed below in no particular order:
|